Viewing CSV files
 Robbert, 15 April 2022
Robbert, 15 April 2022
In data science projects, data comes in many formats. Ideally, you can directly retrieve the data from the data source. But that’s not always possible. You (temporarily) store files in your project directory most of the time. In our Data Science template, you still find a directory to store these files.
CSV is one of the file formats used to store data. In AskAnna you could already open a CSV file, but then you got the raw version. It’s similar to opening a CSV file in a text editor. You can read it, but it’s hard to interpret it.
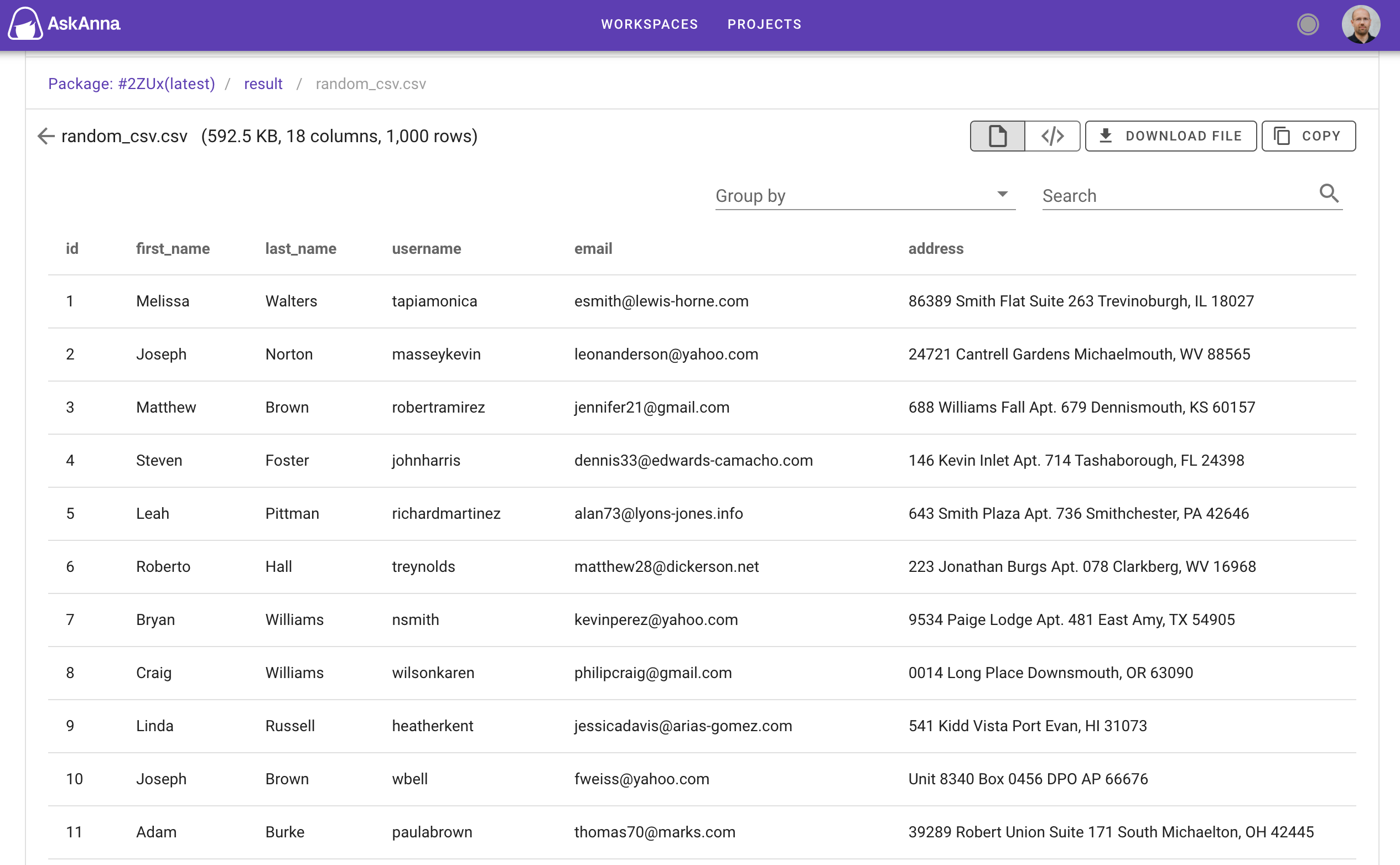
That’s why we added a pretty view for CSV files in AskAnna. We present you the table format when you open a CSV file in AskAnna.
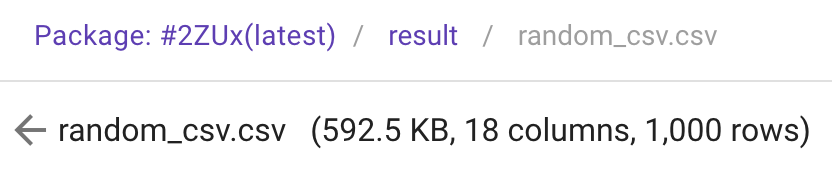
We also build some additional features to make your life a little easier. For example, next to the file name and size you can now find how many columns and rows are found in the CSV file:
Another feature you can use is that you can sort every column in the table. For now it’s only alphanumeric sorting. Not ideal for date-time columns, but for the rest it should work.
You can also group by the data on a column and expand/collapse the rows when you group by the data. Also, you could use this to get the unique values of a column quickly.
Are you looking for a specific record in your data set? You can use the search field for this. I found this especially useful while checking run results and artifacts when looking for the prediction of a specific product category.
The pretty view for CSV files is added to any project files. When opening CSV files in the code section, run results or run artifacts, you get it.
Finally, you can also still open the raw version of the file. But isn’t it prettier to check the data in table format?
Of course, features are never finished. Do you have an idea about what we should add? Let us know!